
[version 14][version 13][version 12][version 11][version 10][version 9][version 8][version 7][version 6]
3.4 Running applications in parallel
This section describes how to run OpenFOAM in parallel on distributed processors. The method of parallel computing used by OpenFOAM is known as domain decomposition, in which the geometry and associated fields are broken into pieces and allocated to separate processors for solution. The process of parallel computation involves: decomposition of mesh and fields; running the application in parallel; and, post-processing the decomposed case as described in the following sections. The parallel running uses the public domain openMPI implementation of the standard message passing interface (MPI) by default, although other libraries can be used.
3.4.1 Decomposition of mesh and initial field data
The mesh and fields are decomposed using the decomposePar utility. The underlying aim is to break up the domain with minimal effort but in such a way to guarantee an economic solution. The geometry and fields are broken up according to a set of parameters specified in a dictionary named decomposeParDict that must be located in the system directory of the case of interest. An example decomposeParDict dictionary can be copied into a case system directory using the foamGet script.
foamGet decomposeParDict
17
18/*
19 Main methods are:
20 1) Geometric: "simple"; "hierarchical", with ordered sorting, e.g. xyz, yxz
21 2) Scotch: "scotch", when running in serial; "ptscotch", running in parallel
22*/
23
24method hierarchical;
25
26simpleCoeffs
27{
28 n (4 2 1); // total must match numberOfSubdomains
29}
30
31hierarchicalCoeffs
32{
33 n (4 2 1); // total must match numberOfSubdomains
34 order xyz;
35}
36
37
38// ************************************************************************* //
The user has a choice of four methods of decomposition, specified by the method keyword as described below.
- simple
- Simple geometric decomposition in which the
domain is split into pieces by direction, e.g. 2 pieces in the
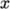 direction, 1 in
direction, 1 in
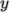 etc.
etc. - hierarchical
- Hierarchical geometric decomposition which
is the same as simple except
the user specifies the order in which the directional split is done,
e.g. first in the -direction, then
the -direction etc.
- scotch
- Scotch decomposition which requires no geometric input from the user and attempts to minimise the number of processor boundaries. The user can specify a weighting for the decomposition between processors, through an optional processorWeights keyword which can be useful on machines with differing performance between processors. There is also an optional keyword entry strategy that controls the decomposition strategy through a complex string supplied to Scotch. For more information, see the source code file: $FOAM_SRC/parallel/decompose/scotchDecomp/scotchDecomp.C
For each method there are a set of coefficients specified in a sub-dictionary of decompositionDict, named <method>Coeffs as shown in the dictionary listing. The full set of keyword entries in the decomposeParDict dictionary are explained below:
- numberOfSubdomains: total number of
subdomains
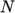 .
. - method: method of decomposition, simple, hierarchical, scotch.
- n: for simple and hierarchical, number of subdomains in
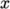 ,
, 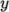 ,
,  (
(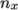
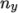
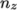 )
) - order: order of hierarchical decomposition, xyz/xzy/yxz…
- processorWeights option for scotch: list of weighting factors (<wt1>…<wtN>) for allocation of cells to processors; <wt1> is the weighting factor for processor 1, etc.; weights are normalised so can take any range of values.
The decomposePar utility is executed in the normal manner by typing
decomposePar
3.4.2 File input/output in parallel
Using standard file
input/output completion, a set of subdirectories will have been
created, one for each processor, in the case directory. The
directories are named processor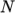 where
where 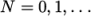 represents a processor
number and contains a time directory, containing the decomposed
field descriptions, and a constant/polyMesh directory containing the
decomposed mesh description.
represents a processor
number and contains a time directory, containing the decomposed
field descriptions, and a constant/polyMesh directory containing the
decomposed mesh description.
While this file structure is well-organised, for large parallel cases, it generates a large number of files. In very large simulations, users can experience problems including hitting limits on the number of open files imposed by the operating system.
As an alternative, the collated file format was introduced in OpenFOAM in which the data for each decomposed field (and mesh) is collated into a single file that is written (and read) on the master processor. The files are stored in a single directory named processors.
The file writing can be threaded allowing the simulation to continue running while the data is being written to file — see below for details. NFS (Network File System) is not needed when using the collated format and, additionally, there is a masterUncollated option to write data with the original uncollated format without NFS.
The controls for the file handling are in the OptimisationSwitches of the global etc/controlDict file:
{
...
//- Parallel IO file handler
// uncollated (default), collated or masterUncollated
fileHandler uncollated;
//- collated: thread buffer size for queued file writes.
// If set to 0 or not sufficient for the file size threading is not used.
// Default: 2e9
maxThreadFileBufferSize 2e9;
//- masterUncollated: non-blocking buffer size.
// If the file exceeds this buffer size scheduled transfer is used.
// Default: 2e9
maxMasterFileBufferSize 2e9;
}
The fileHandler can be set for a specific simulation by:
- over-riding the global OptimisationSwitches {fileHandler …;} in the case controlDict file;
- using the -fileHandler command line argument to the solver;
- setting the $FOAM_FILEHANDLER environment variable.
A foamFormatConvert utility allows users to convert files between the collated and uncollated formats, e.g.
mpirun -np 2 foamFormatConvert -parallel -fileHandler uncollated
$FOAM_TUTORIALS/heatTransfer/buoyantFoam/iglooWithFridges
Collated file handling runs faster with threading, especially on large cases. But it requires threading support to be enabled in the underlying MPI. Without it, the simulation will “hang” or crash. For openMPI, threading support is not set by default prior to version 2, but is generally switched on from version 2 onwards. The user can check whether openMPI is compiled with threading support by the following command:
ompi_info -c | grep -oE "MPI_THREAD_MULTIPLE[^,]*"
Note: if threading is not enabled in the MPI, it must be disabled for collated file handling by setting in the global etc/controlDict file:
maxThreadFileBufferSize 0;
When using the masterUncollated file handling, non-blocking MPI communication requires a sufficiently large memory buffer on the master node. maxMasterFileBufferSize sets the maximum size of the buffer. If the data exceeds this size, the system uses scheduled communication.
3.4.3 Running a decomposed case
A decomposed OpenFOAM case is run in parallel using the openMPI implementation of MPI.
openMPI can be run on a local multiprocessor machine very simply but when running on machines across a network, a file must be created that contains the host names of the machines. The file can be given any name and located at any path. In the following description we shall refer to such a file by the generic name, including full path, <machines>.
The <machines>
file contains the names of the machines listed one machine per line.
The names must correspond to a fully resolved hostname in the
/etc/hosts file of the machine
on which the openMPI is run.
The list must contain the name of the machine running the
openMPI. Where a machine node
contains more than one processor, the node name may be followed by
the entry cpu=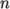 where is the number
of processors openMPI should
run on that node.
where is the number
of processors openMPI should
run on that node.
For example, let us imagine a user wishes to run openMPI from machine aaa on the following machines: aaa; bbb, which has 2 processors; and ccc. The <machines> would contain:
aaa
bbb cpu=2
ccc
An application is run in parallel using mpirun.
mpirun --hostfile <machines> -np <nProcs>
<foamExec> <otherArgs> -parallel > log &
mpirun --hostfile machines -np 4 foamRun -parallel > log &
3.4.4 Distributing data across several disks
Data files may need to be distributed if, for example, if only local disks are used in order to improve performance. In this case, the user may find that the root path to the case directory may differ between machines. The paths must then be specified in the decomposeParDict dictionary using distributed and roots keywords. The distributed entry should read
distributed yes;
roots
<nRoots>
(
"<root0>"
"<root1>"
…
);
Each of the processor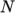 directories should be
placed in the case directory at each of the root paths specified in
the decomposeParDict
dictionary. The system
directory and files within the
constant directory must also
be present in each case directory. Note: the files in the
constant directory are needed,
but the polyMesh directory is
not.
directories should be
placed in the case directory at each of the root paths specified in
the decomposeParDict
dictionary. The system
directory and files within the
constant directory must also
be present in each case directory. Note: the files in the
constant directory are needed,
but the polyMesh directory is
not.
3.4.5 Post-processing parallel processed cases
When post-processing cases that have been run in parallel the user has two options:
- reconstruction of the mesh and field data to recreate the complete domain and fields, which can be post-processed as normal;
- post-processing each segment of decomposed domain individually.
After a case has been run in parallel, it can be
reconstructed for post-processing. The case is reconstructed by
merging the sets of time directories from each processor directory into a single
set of time directories. The reconstructPar utility performs such a reconstruction by
executing the command:
reconstructPar
The user may post-process decomposed cases using the paraFoam post-processor, described in section 7.1 . The whole simulation can be post-processed by reconstructing the case or alternatively it is possible to post-process a segment of the decomposed domain individually by simply treating the individual processor directory as a case in its own right.
